# PostgresSQL internal
This series focuses on understanding the internal structure of PostgreSQL (opens new window). PostgreSQL is a powerful, open source object-relational database system that has earned it a strong reputation for reliability, feature robustness, and performance. It's composed of integrated subsystems, each with its own complex features, that reliably work together.
Although understanding of the internal mechanism is crucial, its complexity prevent it. Kindly note that the documentation guide for these articles have been inspired by after reading Hironobu SUZUKI (opens new window) work. In this first article we are going to learn a summary of the basic knowledge of PostgresSQL to help read the subsequent chapters.
In this chapter, we will be discussing the following concepts;
- The logical structure of a database cluster
- The physical structure of a database cluster
- The internal layout of a heap table file
- The methods of writing and reading data to a table
# Logical Structure of Database Cluster
A database cluster is a collection of databases managed by a PostgreSQL server. All the database objects in PostgreSQL are internally managed by respective object identifiers (OIDs), which are unsigned 4-byte integers. The relations between database objects and their respective OIDs are stored in appropriate system catalogs (opens new window), depending on the type of objects. For example, OIDs of heap tables are stored in pg_class

# Physical Structure of Database Cluster
A database cluster basically is one directory referred to as base directory, and it contains subdirectories and configuration files. The configurations and data files used by the database cluster are stored together within the cluster's data directory, commonly referred to as PGDATA. Multiple clusters, managed by different server instances, can exist on the same machine.
The main files and subdirectories under the layout of the database cluster has been described in the
manual (opens new window). The screenshot below highlights an overview
of the layout
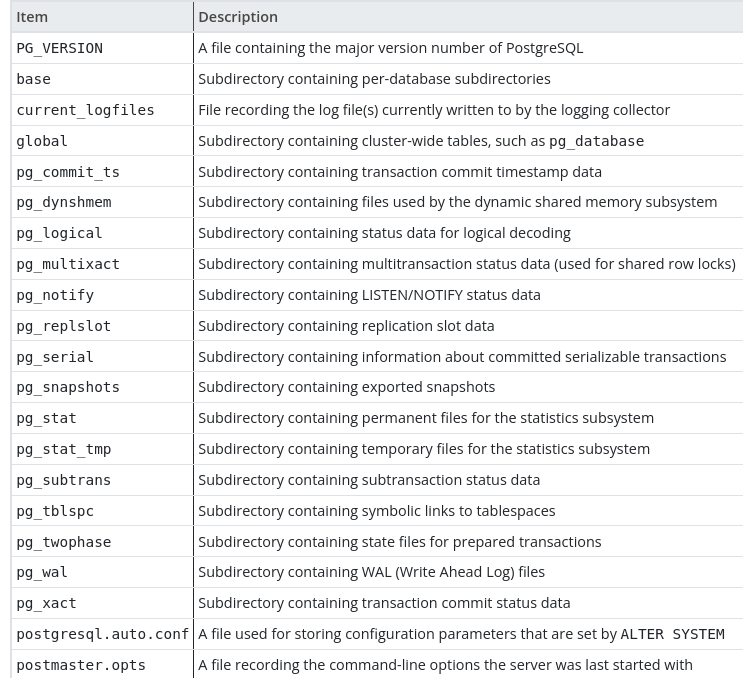
# Layout of Databases
A database on the other hand, is a subdirectory under the base subdirectory. Each of the tables and indexes is (at least) one file stored under the subdirectory of the database to which it belongs.
The database directory names are identical to the respective OIDs. For example, when the OID of a database is 28485, its subdirectory name is 28485.
Each table (except foreign & partition tables) or index whose size is less than 1GB is a single file stored under the database directory it belongs to.
Tables and indexes as database objects, are internally managed by individual OIDs, while those data files are managed by the variable, relfilenode.
The relfilenode values of tables and indexes are changed by the TRUNCATE, REINDEX, CLUSTER commands. When a table is truncated, PostgresSQL assigns a new relfilenode to the table, removes the old data file, and creates a new one.
When the file size of tables and indexes exceeds 1GB, PostgreSQL creates a new file named like relfilenode.1 and uses it. If the new file has been filled up, next new file named like relfilenode.2 will be created, and so on.
Another important files are the free space map and visibility map which are suffixed respectively with '_fsm' and '_vm'. These files store the free space capacity, and the visibility of each page within the table file.
# Tablespaces
PostgreSQL also supports tablespaces, which is a directory that contains some data outside of the base directory. A tablespace is created under the directory specified when you issue CREATE TABLESPACE statement, and under that directory, the version-specific subdirectory (e.g., PG_14_202011044) will be created.
For example, if you create a tablespace 'new_tblspc' at '/home/postgres/tblspc', whose oid is 16386, a subdirectory such as 'PG_14_202011044' would be created under the tablespace.
The tablespace directory is addressed by a symbolic link from the pg_tblspc subdirectory, and the link name is the same as the OID value of tablespace.
# Internal Layout of a Heap Table File
The data file (heap table, index, the free space map and visibility map) is divided into pages (or blocks) of fixed length, the default is 8kb.
The pages within each file are numbered sequentially from 0, and such numbers are called as block numbers. If the file has been filled up, PostgreSQL adds a new empty page to the end of the file to increase the file size.
The Internal layout of pages depends on the data file type
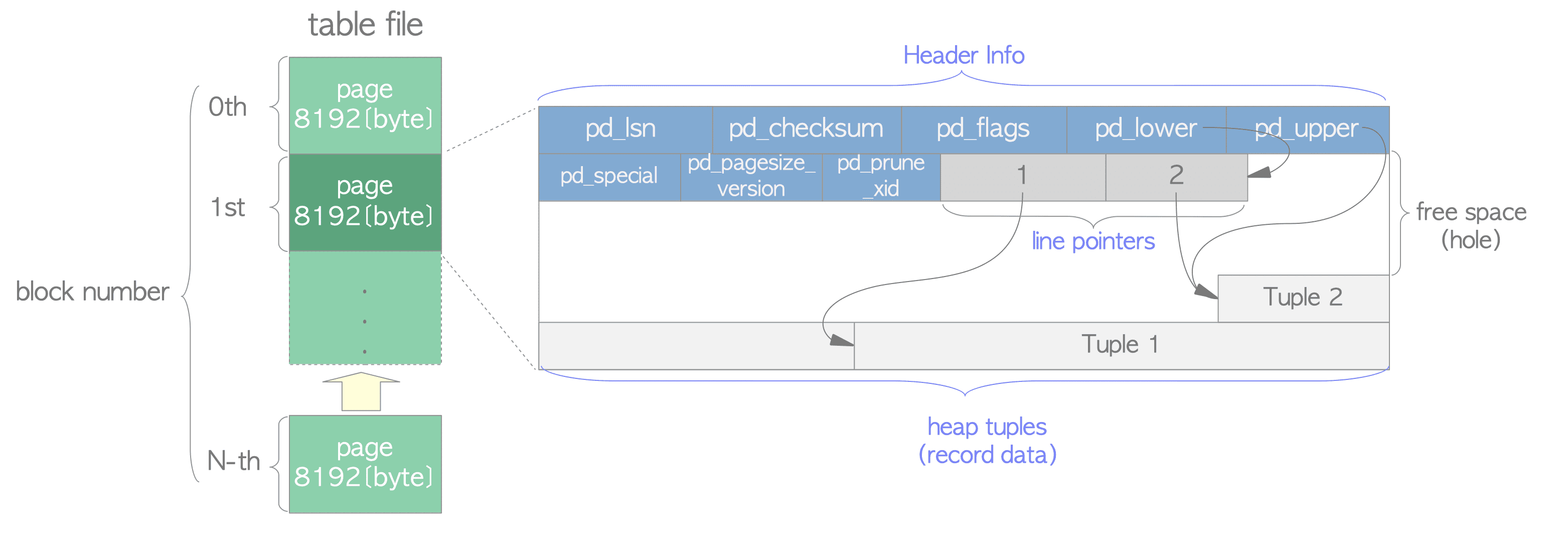
A page within a table contains three kinds of data:
heap tuple(s)
A heap tuple is a record data itself. They are stacked in order from the bottom of the pageline/item pointer(s)
A line pointer (4 byte long) holds a pointer to each heap tuple. They form a simple array, which plays the role of index to the tuples. Each index is numbered sequentially from 1, and called offset number. When a new tuple is added to the page, a new line pointer is also pushed onto the array to point to the new one.header data
A header data defined by the structure PageHeaderData is allocated in the beginning of the page. It is 24 byte long and contains general information about the page. The major variables of the structure are:- pd_lsn - stores LSN of XLOG record written by the last change of the page
- pd_checksum - stores the checksum value of the page
- pd_lower, pd_upper - pd_lower points to the end of line pointers, and pd_upper to the beginning of the newest heap tuple.
- pd_special - stores index information.
An empty space between the end of line pointers and the beginning of the newest tuple is referred to as free space or hole.
To identify a tuple within the table, tuple identifier (TID) is internally used. A TID comprises a pair of values: the block number of the page that contains the tuple, and the offset number of the line pointer that points to the tuple.
In addition, heap tuple whose size is greater than about 2 KB is stored and managed using a method called TOAST (The Oversized-Attribute Storage Technique).
# The Methods of Writing and Reading Tuples
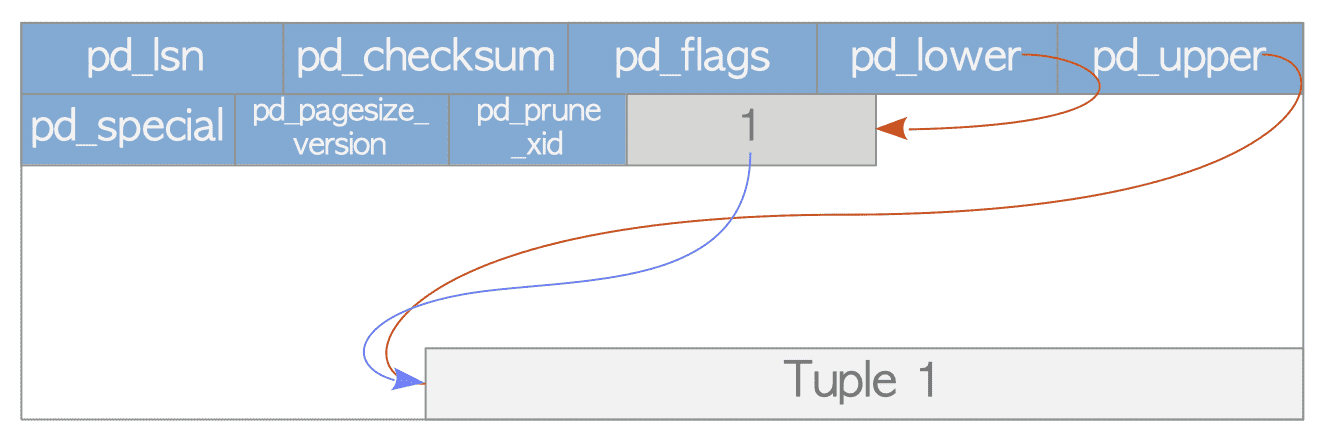
# Reading
Suppose a table composed of one page which contains just one heap tuple. The pd_lower of this page points to the first line pointer, and both the line pointer and the pd_upper point to the first heap tuple.
When the second tuple is inserted, it is placed after the first one. The second line pointer is pushed onto the first one, and it points to the second tuple. The pd_lower changes to point to the second line pointer, and the pd_upper to the second heap tuple.
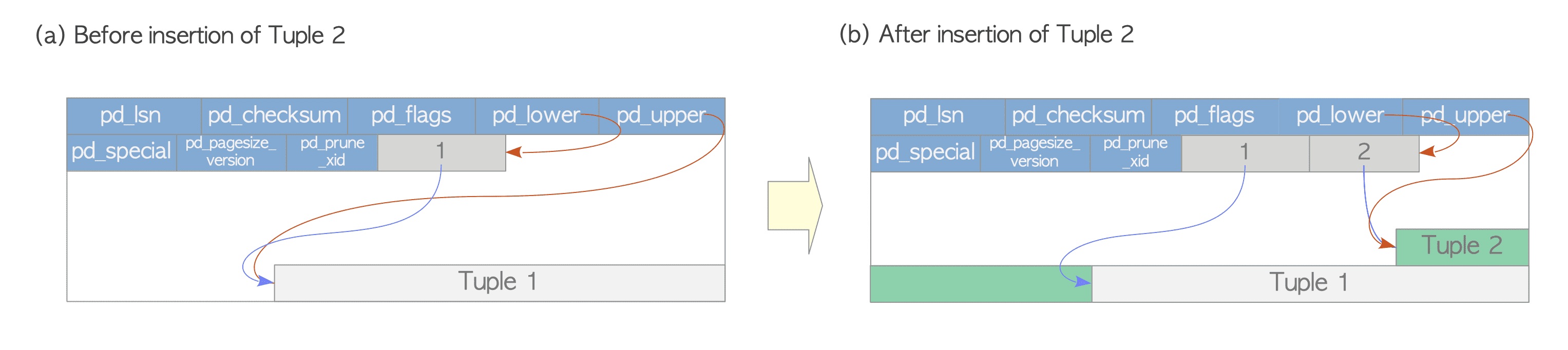
# Writing
There are two typical methods of reading data; sequential scan and B-tree index scan
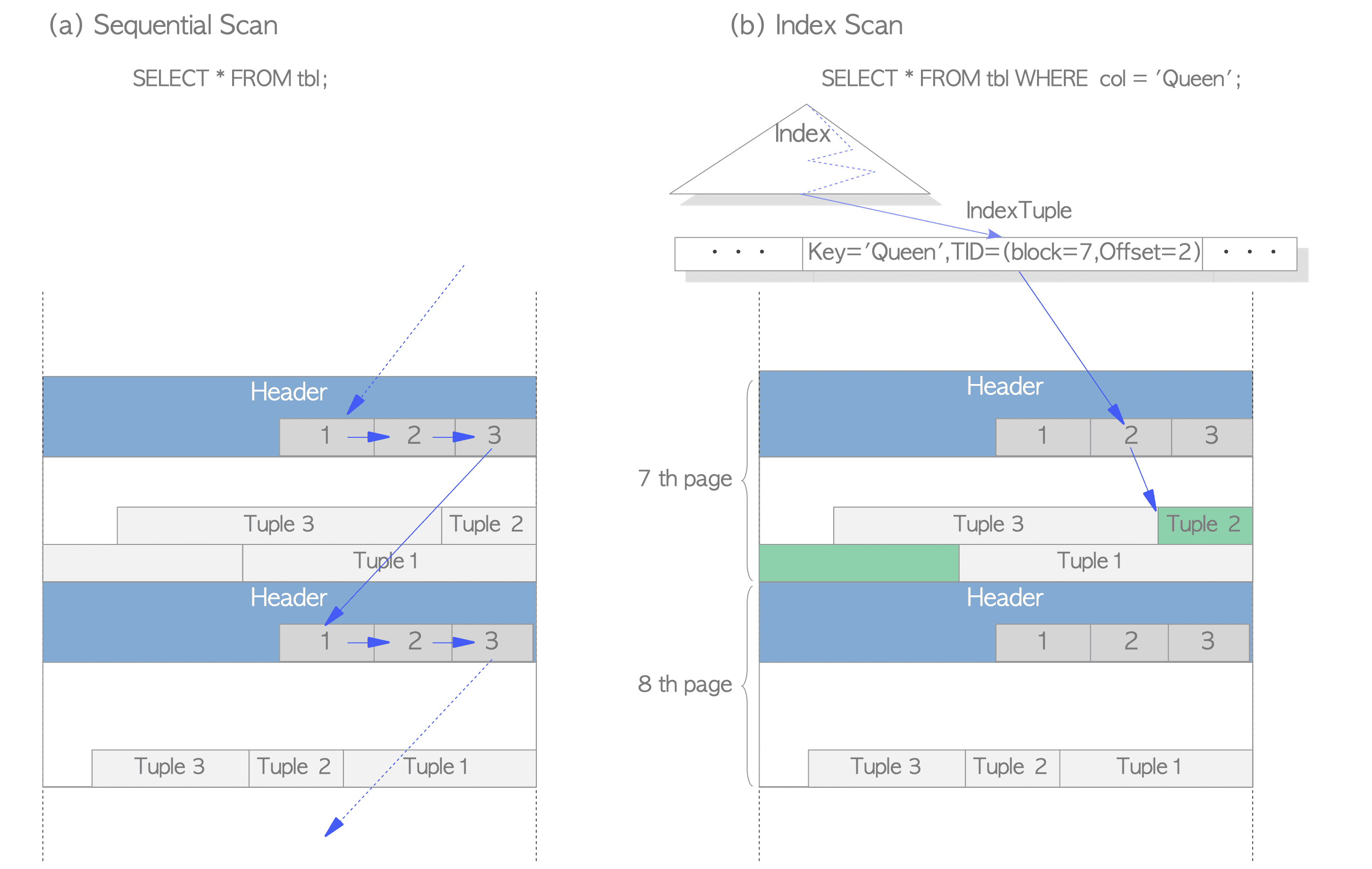
- Sequential scan – All tuples in all pages are sequentially read by scanning all line pointers in each page.
- B-tree index scan – An index file contains index tuples, each of which is composed of an index key and a TID pointing to the target heap tuple. If the index tuple with the key that you are looking for has been found, PostgreSQL reads the desired heap tuple using the obtained TID value.
# Closing thoughts
In this chapter, we learned the logical and physical structure of a postgreSQL database clusters, how data is read, written, and the arrangement of the heap file. In the next chapter, will look into the memory and process architecture
